


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
山田 進; 町田 昌彦; 今村 俊幸*
応用数理, 15(2), p.153 - 158, 2005/06
強相関フェルミ原子ガスの量子物性を計算する際に現れる超大規模なハミルトニアン行列の固有値問題を、地球シミュレータ上で高速に計算するために、並列化,ベクトル化手法の開発を行った。この方法では、問題の物理的性質からハミルトニアン行列の非零要素が規則的に分布することを利用する。この手法を用いることにより、1200億次元のハミルトニアン行列の基底状態を数分で計算可能とし、これまで知られていなかった超流動の発現機構を発見することに成功した。
山田 進; 町田 昌彦; 今村 俊幸*
情報処理学会論文誌; コンピューティングシステム(インターネット), 45(SIG6(ACS6)), p.161 - 170, 2004/05
強相関電子系の電子状態を求める際に現れる超大規模なハミルトニアン行列の固有値のベクトル・並列計算法を提案した。このハミルトニアン行列は小さい行列の直積の形で表せるため、本研究ではその構造を利用し、ベクトル計算する際のメモリアクセスが連続や奇数等間隔になるような計算方法を提案し、実際の計算から通常用いられているアクセスが間接指標となる方法より約4倍高速に計算できることを確認した。また上記の行列の形を利用し、通信量及び演算が均等に分割されている並列計算方法を提案した。これらの提案手法により1次元24サイトのd-pモデルに対応する約180億次元のハミルトニアン行列の最小固有値及び固有ベクトルを地球シミュレータを用いて計算し、提案した並列計算手法は均等に負荷分散ができ、また通信の待ち時間が少ないため、通常用いられる並列計算手法より4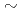 5倍高速に計算できることを確認した。
5倍高速に計算できることを確認した。
山田 進; 今村 俊幸*
計算工学講演会論文集, 8(2), p.753 - 756, 2003/05
量子問題などの固有値計算においては大規模な対称疎行列の固有値計算を高速に行う必要がある。このような大規模な対称疎行列の固有値問題に適した解法にはランチョス法がある。このランチョス法の並列計算時のデータの分割方法と通信の関係を調査し、通信量が少なくなる分割方法,送受信の競合が発生しにくい通信方法を考案した。また、メモリを節約する計算方法を提案した。これらの結果をもとに並列計算ルーチンを開発した。VPP5000(8PE)での並列計算により、この開発したルーチンが4億次元の対称疎行列の最小固有値及び固有ベクトルを求められることが確認できた。
廣田 悠輔*; 山田 進; 今村 俊幸*; 佐々 成正; 町田 昌彦
no journal, ,
行列に対する固有値問題においてその数値解は行列の次数増加に伴い、丸め誤差による有効桁数の減少が見られる。この精度不足問題を解決するため、我々は2012年から4倍精度固有値問題ソルバーの開発を行ってきた。通常の固有値問題に対するソルバーがQPEigenKで一般化固有値問題がQPEigenGである。本研究ではQPEigenKとQPEigenGの計算性能と計算精度を京コンピューター上で計測した。その結果、本ソルバーは大規模固有値問題を比較的短時間で解くことができ、並列計算において高いスケーラビリティを有していることを示すことができた。
 固有値計算の収束加速
固有値計算の収束加速山口 響*; 遠藤 知弘*; 山本 章夫*; 多田 健一
no journal, ,
非増倍体系における固有値の数値解は逆べき乗法による反復計算により求めることができるが、多くの反復回数が必要となる。そこで本研究では、データ駆動型アルゴリズムである動的モード分解(DMD)による収束加速法を適用した固有値計算コードを作成し、その有効性について検証した。
今村 俊幸*; 伊奈 拓也; 廣田 悠輔*; 井戸村 泰宏
no journal, ,
CPUとGPUにおける多様な並列実行モデルが提唱される中で、数値計算ライブラリもそれらに対応した変種を作成しなくてはならない。現状、NVIDIAの環境で複数のバッチ実行から大規模な数値計算までを支えるcuSolverが存在する。また、テネシー大学のMAGMAも標準数値計算ライブラリの地位を得ている。国内の固有値ソルバプロジェクトに限ればEigenExaの開発の一環としてEigenGやEigenG-Batchedを試験実装している。さらに、GPUスパコン環境に対応するMPI並列向けの実装による大規模実装もある。本報告では、これらGPU単体やCPU+GPUの混成環境における固有値計算ソルバーの動向を調査し、測定可能なライブラリについては性能評価を行いGPU環境における今後の固有値計算について議論する。
